We have implemented functionality to allow BHL Staff to upload transcriptions in place of the automatically-generated OCR (Optical Character Recognition) text for digitized materials in BHL’s collection. This functionality supports transcriptions generated as part of in-house or crowdsourced transcription projects hosted by BHL Partners. The Show Text tab now indicates whether the text has been:
- automatically generated and uncorrected;
- automatically generated and error corrected, by machines, which may still include inconsistencies;
- or manually transcribed by humans.
Please note that BHL’s OCR is generated by its Internet Archive digitization partner using Tesseract Open Source OCR (as of 2020) or ABBYYFineReader.
Web-based crowdsource transcription projects are largely managed through the following providers, DigiVol, FromThePage, and Smithsonian Transcription Center.
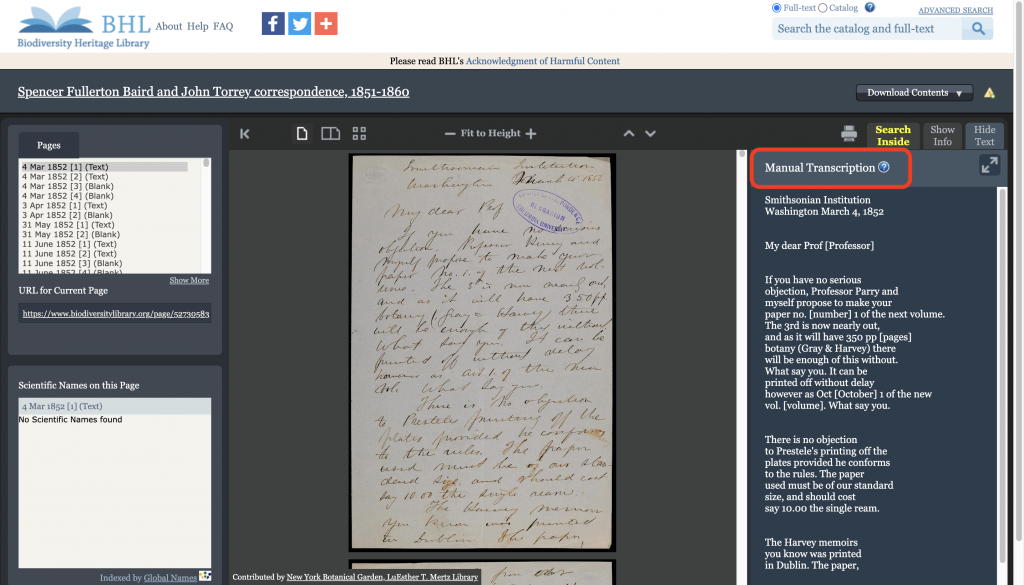
Especially for archival materials, like field notes and correspondence with handwritten text, transcriptions make these items full-text searchable and enable our taxonomic name recognition software to index scientific names within their pages. Since the transcribed text can be viewed alongside the digitized page image, users can also more easily read materials with difficult-to-decipher handwriting. Thus, this new functionality makes it easier for researchers and the public to explore these valuable primary source materials and access specific information from their pages.
Interested in transcribing materials? Several BHL Partners have transcription projects on various crowdsourcing platforms. Follow the links below to explore the opportunities and get involved:
- Auckland War Memorial Museum Tamaki Paenga Hira on FromThePage
- Ernst Mayr Library of Harvard University on DigiVol
- Harvard Botany Libraries on FromThePage
- Lenhardt Library, Chicago Botanic Garden on FromThePage
- The John Torrey Papers from The New York Botanical Garden on FromThePage
- Smithsonian Institution Archives on the Smithsonian Transcription Center
- Ukrainian Collection items from the National Agricultural Library (NAL) on FromThePage
Tags: crowdsourcing, citizen science, transcription, OCR, full text search, archives